უხეში ძალის მეთოდი არის გადაჭრის პირდაპირი მიდგომა
პრობლემის შესახებ, როგორც წესი, პირდაპირ ეფუძნება პრობლემის განცხადებას და მის მიერ გამოყენებული ცნებების განმარტებებს.
უხეში ძალის ალგორითმს ზოგადი საძიებო პრობლემის გადასაჭრელად ეწოდება თანმიმდევრული ძიება. ეს ალგორითმი უბრალოდ ადარებს მოცემული სიის ელემენტებს საძიებო კლავიშთან სათითაოდ, სანამ არ მოიძებნება მითითებული გასაღების მნიშვნელობის მქონე ელემენტი (წარმატებული ძიება) ან არ შემოწმდება მთელი სია, მაგრამ სასურველი ელემენტი ვერ მოიძებნება (მოძებნა წარუმატებელი). ხშირად გამოიყენება მარტივი დამატებითი ხრიკი: თუ დაამატებთ საძიებო კლავიშს სიის ბოლოს, ძიება აუცილებლად წარმატებული იქნება, შესაბამისად, შეგიძლიათ წაშალოთ სიის შევსების შემოწმება ალგორითმის თითოეულ გამეორებაში. შემდეგი არის ფსევდოკოდი ასეთი გაუმჯობესებული ვერსიისთვის; ვარაუდობენ, რომ შეყვანის მონაცემები არის მასივის სახით.
თუ თავდაპირველი სია დალაგებულია, შეგიძლიათ ისარგებლოთ კიდევ ერთი გაუმჯობესებით: ასეთ სიაში ძიება შეიძლება შეწყდეს, როგორც კი აღმოჩნდება ელემენტი, რომელიც არ არის საძიებო კლავიშზე ნაკლები. თანმიმდევრული ძიება იძლევა უხეში ძალის მეთოდის შესანიშნავ ილუსტრაციას, მისი დამახასიათებელი ძლიერი მხარეებით (სიმარტივე) და სუსტი მხარეებით (დაბალი ეფექტურობა).
სავსებით აშკარაა, რომ ამ ალგორითმის გაშვების დრო შეიძლება განსხვავდებოდეს ძალიან ფართო საზღვრებში ერთი და იგივე ზომის n სიისთვის, ე.ი. როდესაც სია არ შეიცავს სასურველ ელემენტს, ან როდესაც სასურველი ელემენტი მდებარეობს სიაში ბოლო, ალგორითმი შეასრულებს ოპერაციების უდიდეს რაოდენობას, კლავიშს ადარებს სიის ყველა n ელემენტს: C(n) = n.
1.2. რაბინის ალგორითმი.
რაბინის ალგორითმი არის ხაზოვანი ალგორითმის მოდიფიკაცია, ის ეფუძნება ძალიან მარტივ იდეას:
წარმოვიდგინოთ, რომ სიტყვა A-ში, რომლის სიგრძეა m, ჩვენ ვეძებთ n სიგრძის X შაბლონს. მოდით ამოვჭრათ n ზომის "ფანჯარა" და გადავიტანოთ შეყვანილი სიტყვის გასწვრივ. ჩვენ გვაინტერესებს შეესაბამება თუ არა სიტყვა „ყუთში“ მოცემულ ნიმუშს. ასოების შედარებას დიდი დრო სჭირდება. ამის ნაცვლად, ჩვენ ვაფიქსირებთ ციფრულ ფუნქციას n სიგრძის სიტყვებზე, შემდეგ პრობლემა შემცირდება რიცხვების შედარებამდე, რაც უდავოდ უფრო სწრაფია. თუ ამ ფუნქციის მნიშვნელობები სიტყვაზე "ყუთში" და ნიმუშზე განსხვავებულია, მაშინ შემთხვევითი არ არის. მხოლოდ იმ შემთხვევაში, თუ მნიშვნელობები ერთი და იგივეა, აუცილებელია თანმიმდევრულად შეამოწმოთ ასო-ასო შესატყვისი“.
ეს ალგორითმი ასრულებს წრფივ გადაკვეთას სტრიქონზე (n ნაბიჯი) და ხაზოვან გადაკვეთას მთელ ტექსტზე (m ნაბიჯი), ასე რომ მთლიანი გაშვების დრო არის O(n+m). ამავდროულად, ჩვენ არ გავითვალისწინებთ ჰეშის ფუნქციის გამოთვლის დროის სირთულეს, რადგან ალგორითმის არსი იმაში მდგომარეობს, რომ ამ ფუნქციის გამოთვლა იმდენად მარტივი უნდა იყოს, რომ მისი მოქმედება გავლენას არ მოახდენს ალგორითმის მთლიან მუშაობაზე.
რაბინის ალგორითმი და თანმიმდევრული ძიების ალგორითმი ყველაზე ნაკლებად შრომატევადი ალგორითმებია, ამიტომ ისინი შესაფერისია გარკვეული კლასის პრობლემების გადასაჭრელად. თუმცა, ეს ალგორითმები არ არის ყველაზე ოპტიმალური.
1.3. Knuth-Moris-Pratt (kmp) ალგორითმი.
KMP მეთოდი იყენებს საძიებო სტრიქონის წინასწარ დამუშავებას, კერძოდ: მის საფუძველზე იქმნება პრეფიქსის ფუნქცია. გამოიყენება შემდეგი იდეა: თუ i სიგრძის სტრიქონის პრეფიქსი (აკა სუფიქსი) ერთ სიმბოლოზე გრძელია, მაშინ ის ასევე არის i-1 სიგრძის ქვესტრიქონის პრეფიქსი. ამრიგად, ჩვენ ვამოწმებთ წინა ქვესტრიქონის პრეფიქსს, თუ ის არ ემთხვევა, მაშინ მისი პრეფიქსის პრეფიქსი და ა.შ. ამით ჩვენ ვპოულობთ ყველაზე დიდ საჭირო პრეფიქსს. შემდეგი კითხვაზე პასუხის ღირსია: რატომ არის პროცედურის გაშვების დრო წრფივი, რადგან ის შეიცავს წყობილ მარყუჟს? პირველ რიგში, პრეფიქსის ფუნქციის მინიჭება ხდება ზუსტად m-ჯერ, დანარჩენ დროს იცვლება k ცვლადი. ამრიგად, პროგრამის მთლიანი გაშვების დრო არის O(n+m), ანუ წრფივი დრო.
ბრინჯი. 11.6. სიის შექმნის პროცედურა ბრინჯი. 11.7. გრაფიკული გამოსახულებადასტის ბრინჯი. 11.8. ორობითი ხის მაგალითი ბრინჯი. 11.9. ხის ორობითი კონვერტაციის ნაბიჯი
დახარისხების პრობლემა დასმულია შემდეგნაირად. დაე, იყოს მთელი რიცხვების მასივი ან რეალური რიცხვები, თქვენ უნდა გადააწყოთ ამ მასივის ელემენტები ისე, რომ გადაწყობის შემდეგ ისინი დალაგდეს შეუმცირებელი თანმიმდევრობით: ფორმულა" src="http://hi-edu.ru/e. -books/xbook691/files/178-2 gif" border="0" align="absmiddle" alt="თუ რიცხვები წყვილში განსხვავებულია, მაშინ ისინი საუბრობენ დალაგებაზე აღმავალი ან კლებადობით. შემდგომში განვიხილავთ შეკვეთის პრობლემას შეუმცირებელი თანმიმდევრობით, ვინაიდან სხვა პრობლემების გადაჭრა შესაძლებელია ანალოგიურად. არსებობს მრავალი დახარისხების ალგორითმი, რომელთაგან თითოეულს აქვს საკუთარი სიჩქარის მახასიათებლები. მოდით შევხედოთ უმარტივეს ალგორითმებს სიჩქარის გაზრდის მიზნით.
დახარისხება გაცვლის მიხედვით (ბუშტი)
ეს ალგორითმი ითვლება ყველაზე მარტივ და ნელა. დახარისხების საფეხური შედგება მასივის გავლით ქვემოდან ზემოდან გადასვლით. ამ შემთხვევაში განიხილება მეზობელი ელემენტების წყვილი. თუ გარკვეული წყვილის ელემენტები არ არის სწორი თანმიმდევრობით, შემდეგ ადგილებს იცვლიან.
მასივის პირველი გავლის შემდეგ, „ყველაზე მსუბუქი“ (მინიმალური) ელემენტი ჩნდება „ზედაზე“ (მაივის დასაწყისში), შესაბამისად, ანალოგია ბუშტთან, რომელიც ცურავს ზემოთ (ნახ. 11.1).  ). შემდეგი გადასასვლელი კეთდება მეორე ელემენტზე ზემოდან, ამიტომ სიდიდით მეორე ელემენტი სწორ პოზიციაზე ამაღლებულია და ა.შ.
). შემდეგი გადასასვლელი კეთდება მეორე ელემენტზე ზემოდან, ამიტომ სიდიდით მეორე ელემენტი სწორ პოზიციაზე ამაღლებულია და ა.შ.
გადასვლები კეთდება მასივის მუდმივად კლებადი ქვედა ნაწილის გასწვრივ, სანამ მხოლოდ ერთი ელემენტი დარჩება. სწორედ აქ მთავრდება დახარისხება, რადგან თანმიმდევრობა დალაგებულია ზრდადობით.
subheading">დახარისხება შერჩევის მიხედვით
შერჩევის დალაგება ოდნავ უფრო სწრაფია, ვიდრე ბუშტუკები. ალგორითმი ასეთია: თქვენ უნდა იპოვოთ მასივის ელემენტი, რომელსაც აქვს ყველაზე მცირე მნიშვნელობა, გადააწყოთ იგი პირველ ელემენტთან, შემდეგ იგივე გააკეთოთ, დაწყებული მეორე ელემენტით და ა.შ. ეს ქმნის დახარისხებულ თანმიმდევრობას ერთი ელემენტის მიყოლებით სწორი თანმიმდევრობით. ჩართულია მე-ე ნაბიჯიაირჩიეთ ელემენტებიდან ყველაზე პატარა a[i]...a[n] და შეცვალეთ იგი a[i]-ით. ნაბიჯების თანმიმდევრობა ნაჩვენებია ნახ. 11.2  .
.
მიმდინარე i საფეხურის რაოდენობის მიუხედავად, a...a[i] თანმიმდევრობა დალაგებულია. ამრიგად, (n - 1)-ე საფეხურზე მთელი თანმიმდევრობა, გარდა a[n]-ისა, დალაგებულია და a[n] ბოლო ადგილზეა მარჯვნივ: ყველა პატარა ელემენტი უკვე წავიდა მარცხნივ.
subheading">მარტივი ჩასმის დალაგება
მასივი იკვეთება და ყოველი ახალი ელემენტი a[i] ჩასმულია შესაბამის ადგილას უკვე შეკვეთილ კოლექციაში a,...,a. ეს მდებარეობა განისაზღვრება a[i]-ის თანმიმდევრული შედარებით a,...,a მოწესრიგებულ ელემენტებთან. ამრიგად, დახარისხებული თანმიმდევრობა "იზრდება" მასივის დასაწყისში.
თუმცა, ბუშტში ან შერჩევის დალაგებაში შესაძლებელი იყო მკაფიოდ იმის თქმა, რომ i-ე საფეხურზე ელემენტები a...a არის სწორ ადგილებში და არ გადაადგილდებიან სხვაგან. მარტივი ჩასმის დალაგების შემთხვევაში შეგვიძლია ვთქვათ, რომ a...a მიმდევრობა დალაგებულია. ამ შემთხვევაში, როგორც ალგორითმი პროგრესირებს, მასში ყველა ახალი ელემენტი იქნება ჩასმული (იხ. მეთოდის დასახელება).
განვიხილოთ ალგორითმის მოქმედებები i-ე საფეხურზე. როგორც ზემოთ აღინიშნა, თანმიმდევრობა ამ ეტაპზე იყოფა ორ ნაწილად: მზა a...a და უწესრიგო a[i]...a[n].
ალგორითმის მომდევნო, i-ე საფეხურზე ვიღებთ a[i]-ს და ჩავსვამთ მასივის დასრულებულ ნაწილში სასურველ ადგილას. შეყვანის თანმიმდევრობის შემდეგი ელემენტისთვის შესაფერისი ადგილის ძიება ხორციელდება მის წინ არსებულ ელემენტთან თანმიმდევრული შედარების გზით. შედარების შედეგიდან გამომდინარე, ელემენტი ან რჩება ამჟამინდელ მდგომარეობაში (ჩასმა დასრულებულია), ან ხდება მათი გაცვლა და პროცესი მეორდება (ნახ. 11.3).  ).
).
ამგვარად, ჩასმის პროცესის დროს X ელემენტს მასივის დასაწყისამდე „ვიცრებით“ ვაჩერებთ if
- ნაპოვნია X-ზე პატარა ელემენტი;
- მიმდევრობის დასაწყისი მიღწეულია.
განისაზღვრება წრფივი ძიების ალგორითმით, როდესაც მთელი მასივი თანმიმდევრულად იკვეთება და მასივის მიმდინარე ელემენტი შედარებულია მოძიებულ ელემენტთან, თუ არსებობს შესაბამისი, ნაპოვნი ელემენტის ინდექს(ებ)ი ახსოვს.
თუმცა, შეიძლება არსებობდეს მრავალი დამატებითი პირობა ძიების პრობლემაში. მაგალითად, მინიმალური და მაქსიმალური ელემენტის ძიება, სტრიქონში ქვესტრიქონის ძიება, უკვე დალაგებულ მასივში ძიება, არსებობს თუ არა სასურველი ელემენტი ინდექსის მითითების გარეშე და ა.შ. მოდით შევხედოთ რამდენიმე ტიპურ საძიებო ამოცანას.
მოძებნეთ ქვესტრიქონი ტექსტში (სტრიქონი). უხეში ძალის ალგორითმი
სტრიქონში ქვესტრიქონის ძიება ხორციელდება მოცემული ნიმუშის მიხედვით, ე.ი. სიმბოლოების გარკვეული თანმიმდევრობა, რომლის სიგრძე არ აღემატება ორიგინალური სტრიქონის სიგრძეს. ძიების ამოცანაა დაადგინოს, შეიცავს თუ არა სტრიქონი მოცემულ შაბლონს და მიუთითოს მდებარეობა (ინდექსი) სტრიქონში, თუ შესატყვისი აღმოჩნდება.
უხეში ძალის ალგორითმი არის უმარტივესი და ნელი და შედგება ტექსტის ყველა პოზიციის შემოწმება ნიმუშის დასაწყისთან შესატყვისად. თუ ნიმუშის დასაწყისი ემთხვევა, მაშინ ნიმუშის და ტექსტის შემდეგი ასო შედარებულია და ასე გრძელდება მანამ, სანამ შემდეგი ასო მთლიანად არ ემთხვევა ნიმუშს ან არ განსხვავდება მისგან.
subtitle">ბოიერ-მურის ალგორითმი
Boyer-Moore-ის ალგორითმის უმარტივესი ვერსია შედგება შემდეგი ნაბიჯებისგან. პირველი ნაბიჯი არის გადაადგილების ცხრილის შექმნა სასურველი ნიმუშისთვის. შემდეგი, ხაზის დასაწყისი და ნიმუში გაერთიანებულია და შემოწმება იწყება ნიმუშის ბოლო სიმბოლოდან. თუ შაბლონის ბოლო სიმბოლო და ხაზის შესაბამისი სიმბოლო არ ემთხვევა ზედ დადგმისას, ნიმუში გადაინაცვლებს ხაზთან შედარებით ოფსეტური ცხრილიდან მიღებული რაოდენობით და შედარება ხდება ხელახლა, დაწყებული ბოლო სიმბოლოდან. ნიმუში. თუ სიმბოლოები ემთხვევა, შედარებულია ნიმუშის ბოლო სიმბოლო და ა.შ. თუ შაბლონის ყველა სიმბოლო ემთხვევა სტრიქონში არსებულ სიმბოლოებს, მაშინ ქვესტრიქონი ნაპოვნია და ძებნა დასრულებულია. თუ შაბლონის ზოგიერთი (არა ბოლო) სიმბოლო არ ემთხვევა სტრიქონის შესაბამის სიმბოლოს, ჩვენ გადავიტანთ შაბლონს ერთი სიმბოლო მარჯვნივ და ხელახლა ვიწყებთ შემოწმებას ბოლო სიმბოლოდან. მთელი ალგორითმი შესრულებულია მანამ, სანამ არ მოიძებნება სასურველი ნიმუში ან სტრიქონის დასასრული.
ბოლო სიმბოლოს შეუსაბამობის შემთხვევაში ცვლის ოდენობა გამოითვლება წესის მიხედვით: შაბლონის ცვლა უნდა იყოს მინიმალური - ისეთი, რომ არ გამოტოვოთ ნიმუშის გაჩენა ხაზში. თუ მოცემული სტრიქონის სიმბოლო გვხვდება შაბლონში, ნიმუში გადაინაცვლებს ისე, რომ სტრიქონის სიმბოლო ემთხვეოდეს ამ სიმბოლოს შაბლონში ყველაზე მარჯვნივ. თუ ნიმუში საერთოდ არ შეიცავს ამ სიმბოლოს, მაშინ ნიმუში გადაინაცვლებს მისი სიგრძის ტოლი რაოდენობით ისე, რომ ნიმუშის პირველი სიმბოლო გადაიტანოს შესამოწმებელი ხაზის მომდევნო სიმბოლოზე.
ნიმუშის თითოეული სიმბოლოს ოფსეტური მნიშვნელობა დამოკიდებულია მხოლოდ ნიმუშის სიმბოლოების თანმიმდევრობაზე, ამიტომ მოსახერხებელია წინასწარ გამოთვალოთ ოფსეტები და შეინახოთ ისინი ერთგანზომილებიანი მასივის სახით, სადაც ანბანის თითოეული სიმბოლოა. შეესაბამება ოფსეტს ნიმუშის ბოლო სიმბოლოსთან შედარებით. მოდით ავხსნათ ყოველივე ზემოთქმული მარტივი მაგალითის გამოყენებით. მოდით იყოს ხუთი სიმბოლოს ნაკრები: a, b, c, d, e და თქვენ უნდა იპოვოთ ნიმუში "abbad" სტრიქონში "abecccacbadbabbad". შემდეგი დიაგრამები ასახავს ალგორითმის ყველა საფეხურს:
formula" src="http://hi-edu.ru/e-books/xbook691/files/ris-page184-1.gif" border="0" align="absmiddle" alt="
დაიწყეთ ძებნა. ნიმუშის ბოლო სიმბოლო არ ემთხვევა სტრიქონის გადაფარვის სიმბოლოს. გადაიტანეთ ნიმუში მარჯვნივ 5 პოზიციით:
formula" src="http://hi-edu.ru/e-books/xbook691/files/ris-page185.gif" border="0" align="absmiddle" alt="
ბოლო სიმბოლო კვლავ არ ემთხვევა სტრიქონის სიმბოლოს. გადაადგილების ცხრილის შესაბამისად, ჩვენ ვცვლით ნიმუშს ორი პოზიციით:
formula" src="http://hi-edu.ru/e-books/xbook691/files/ris-page185-2.gif" border="0" align="absmiddle" alt="
ახლა, ცხრილის შესაბამისად, ჩვენ ვცვლით შაბლონს ერთი პოზიციით და ვიღებთ ნიმუშის სასურველ მოვლენას:
formula" src="http://hi-edu.ru/e-books/xbook691/files/ris-page185-4.gif" border="0" align="absmiddle" alt="
formula" src="http://hi-edu.ru/e-books/xbook691/files/ris-page186.gif" border="0" align="absmiddle" alt="
BMSearch ფუნქცია აბრუნებს P ნიმუშის პირველი გამოჩენის პირველი სიმბოლოს პოზიციას S სტრიქონში. თუ P თანმიმდევრობა არ მოიძებნება S-ში, ფუნქცია აბრუნებს 0-ს (გაიხსენეთ, რომ ObjectPascal-ში იწყება სიმბოლოების ნუმერაცია სტრიქონში. 1-ზე). StartPos პარამეტრი საშუალებას გაძლევთ მიუთითოთ პოზიცია S სტრიქონში, საიდანაც დაიწყება ძებნა. ეს შეიძლება იყოს სასარგებლო, თუ გსურთ იპოვოთ P-ის ყველა შემთხვევა S-ში. სტრიქონის თავიდანვე მოსაძებნად, თქვენ უნდა დააყენოთ StartPos 1-ზე. თუ ძიების შედეგი არ არის ნულოვანი, მაშინ იმისათვის, რომ იპოვოთ შემდეგი. S-ში P-ის გამოჩენა, თქვენ უნდა დააყენოთ StartPos მნიშვნელობის „წინა შედეგი პლუს ნიმუშის სიგრძე“ ტოლი.
ორობითი (ორობითი) ძებნა
ორობითი ძებნა გამოიყენება, თუ მასივი, რომელშიც ის შესრულებულია, უკვე დაკვეთილია.
ცვლადები Lb და Ub შეიცავენ, შესაბამისად, მასივის სეგმენტის მარცხენა და მარჯვენა საზღვრებს, სადაც მდებარეობს სასურველი ელემენტი. ძებნა ყოველთვის იწყება სეგმენტის შუა ელემენტის შემოწმებით. თუ სასურველი მნიშვნელობა შუა ელემენტზე ნაკლებია, მაშინ უნდა გადახვიდეთ ძებნაზე სეგმენტის ზედა ნახევარში, სადაც ყველა ელემენტი ნაკლებია ახლახან შემოწმებულზე. სხვა სიტყვებით რომ ვთქვათ, Ub-ის მნიშვნელობა ხდება (M-1) და მომდევნო გამეორებისას მოწმდება ორიგინალური მასივის ნახევარი. ამრიგად, ყოველი შემოწმების შედეგად, საძიებო არე ნახევრად ვიწროვდება. მაგალითად, თუ მასივში არის 100 რიცხვი, მაშინ პირველი გამეორების შემდეგ საძიებო არე მცირდება 50 რიცხვამდე, მეორის შემდეგ - 25-მდე, მესამეს შემდეგ 13-მდე, მეოთხეს შემდეგ 7-მდე და ა.შ..gif" border="0" align=" absmiddle" alt="
მონაცემთა დინამიური სტრუქტურები ეფუძნება მაჩვენებლების გამოყენებას და სტანდარტული პროცედურების და ფუნქციების გამოყენებას პროგრამის მუშაობის დროს მეხსიერების განაწილების/განთავისუფლებისთვის. ისინი განსხვავდებიან სტატიკური მონაცემთა სტრუქტურებისგან, რომლებიც აღწერილია ტიპებსა და მონაცემთა განყოფილებებში. როდესაც პროგრამაში აღწერილია სტატიკური ცვლადი, მაშინ პროგრამის შედგენისას, ოპერატიული მეხსიერება გამოიყოფა ცვლადის ტიპის მიხედვით. თუმცა, გამოყოფილი მეხსიერების ზომის შეცვლა შეუძლებელია.
მაგალითად, თუ მითითებულია მასივი
Var S: char-ის მასივი,
მაშინ მას ერთხელ პროგრამის შესრულების დასაწყისში 10 ბაიტი ოპერატიული მეხსიერება ეთმობა.
დინამიურ სტრუქტურებს ახასიათებს სტრუქტურის ზომის (ელემენტების რაოდენობა) არათანმიმდევრულობა და არაპროგნოზირებადობა მისი დამუშავებისას.
იმის გამო, რომ დინამიური სტრუქტურის ელემენტები განლაგებულია მეხსიერების არაპროგნოზირებად მისამართებზე, ასეთი სტრუქტურის ელემენტის მისამართი არ შეიძლება გამოითვალოს საწყისი ან წინა ელემენტის მისამართიდან.
დინამიური სტრუქტურის ელემენტებს შორის კავშირების დასამყარებლად გამოიყენება მაჩვენებლები, რომელთა მეშვეობითაც მყარდება აშკარა კავშირები ელემენტებს შორის. მონაცემთა ამ წარმოდგენას მეხსიერებაში ეწოდება თანმიმდევრული. დინამიური სტრუქტურის ელემენტი შედგება ორი ველისაგან:
- ინფორმაციის ველი ან მონაცემთა ველი, რომელიც შეიცავს მონაცემებს, რისთვისაც შექმნილია სტრუქტურა; ზოგადად, საინფორმაციო ველი თავად არის ინტეგრირებული სტრუქტურა: ჩანაწერი, ვექტორი, მასივი, სხვა დინამიური სტრუქტურა და ა.შ.;
- ბმული ველები, რომლებიც შეიცავს ერთ ან მეტ მაჩვენებელს ამ ელემენტსსხვა სტრუქტურულ ელემენტებთან ერთად.
როდესაც მონაცემთა თანმიმდევრული წარმოდგენა გამოიყენება აპლიკაციის პრობლემის გადასაჭრელად, მხოლოდ ინფორმაციის ველის შიგთავსი ხდება „ხილული“ საბოლოო მომხმარებლისთვის, ხოლო ბმული ველი გამოიყენება მხოლოდ პროგრამისტი-დეველოპერის მიერ.
მონაცემთა თანმიმდევრული პრეზენტაციის უპირატესობები:
- სტრუქტურებში მნიშვნელოვანი ცვალებადობის უზრუნველყოფის უნარი;
- სტრუქტურის ზომის შეზღუდვა მხოლოდ მანქანის მეხსიერების ხელმისაწვდომი რაოდენობით;
- სტრუქტურის ელემენტების ლოგიკური თანმიმდევრობის შეცვლისას საჭირო არ არის მონაცემთა მეხსიერებაში გადატანა, არამედ მხოლოდ მაჩვენებლების გასწორება;
- მეტი სტრუქტურული მოქნილობა.
ამავდროულად, თანმიმდევრული წარმოდგენა არ არის ნაკლოვანებების გარეშე, რომელთაგან მთავარია:
ბოლო ნაკლი ყველაზე სერიოზულია და სწორედ ეს ზღუდავს მონაცემთა თანმიმდევრული წარმოდგენის გამოყენებას. თუ მეზობელ მონაცემთა წარმოდგენაში (მასივებში) რომელიმე ელემენტის მისამართის გამოსათვლელად, ყველა შემთხვევაში გვქონდა მხოლოდ ელემენტის ნომერი და ინფორმაცია, რომელიც შეიცავს სტრუქტურის აღმწერს, მაშინ დაკავშირებული წარმოდგენისთვის ელემენტის მისამართი ვერ გამოითვლება წყაროს მონაცემებიდან. . დაკავშირებული სტრუქტურის აღმწერი შეიცავს ერთ ან რამდენიმე მაჩვენებელს, რომელიც საშუალებას გაძლევთ შეიყვანოთ სტრუქტურაში, შემდეგ კი საჭირო ელემენტის ძიება ხორციელდება მაჩვენებლების ჯაჭვის შემდეგ ელემენტიდან ელემენტამდე. ამიტომ, დაკავშირებული წარმოდგენა თითქმის არასოდეს გამოიყენება ამოცანებში, სადაც მონაცემთა ლოგიკური სტრუქტურა არის ვექტორის ან მასივის სახით - ელემენტის ნომრით წვდომით, მაგრამ ხშირად გამოიყენება ამოცანებში, სადაც ლოგიკური სტრუქტურა მოითხოვს სხვა საწყისი წვდომის ინფორმაციას (ცხრილები, სიები, ხეები და ა.შ.).
პროგრამირებაში გამოყენებული დინამიური სტრუქტურები მოიცავს:
- დინამიური მასივები (განხილულია მე-6 თემაში);
- ხაზოვანი სიები;
- დასტის;
- რიგი, დეკ;
- ხეები.
სია არის მოწესრიგებული ნაკრები, რომელიც შედგება ელემენტების ცვლადი რაოდენობისგან, რომლებზეც გამოიყენება ჩართვისა და გამორიცხვის ოპერაციები. სიას, რომელიც ასახავს ელემენტებს შორის მიმდებარე ურთიერთობებს, ეწოდება წრფივი. სიის სიგრძე უდრის მასში შემავალი ელემენტების რაოდენობას ნულოვანი სიგრძის სიას ეწოდება ცარიელი. ხაზოვანი დაკავშირებული სიები არის მონაცემთა უმარტივესი დინამიური სტრუქტურები.
გრაფიკულად, სიებში კავშირები მოხერხებულად არის წარმოდგენილი ისრებით, როგორც ეს ნაჩვენებია მაჩვენებლების აღწერის განყოფილებაში. თუ სიის ელემენტი არ არის დაკავშირებული სხვასთან, მაშინ მაჩვენებლის ველი ივსება მნიშვნელობით, რომელიც არ მიუთითებს არცერთ ელემენტზე (null მაჩვენებელი). პასკალში ასეთი ბმული აღინიშნება Nil-ით, ხოლო დიაგრამაში იგი მითითებულია გადახაზული მართკუთხედით. ქვემოთ მოცემულია სტრუქტურა ცალკე დაკავშირებული სია(ნახ. 11.4  ), ე.ი. კავშირი გადადის ერთი სიის ელემენტიდან მეორეზე ერთი მიმართულებით. აქ ველი D არის ინფორმაციის ველი, რომელიც შეიცავს მონაცემებს (პასკალის ენაზე დაშვებული ნებისმიერი ტიპი), ველი N (NEXT) არის სიის შემდეგი ელემენტის მაჩვენებელი.
), ე.ი. კავშირი გადადის ერთი სიის ელემენტიდან მეორეზე ერთი მიმართულებით. აქ ველი D არის ინფორმაციის ველი, რომელიც შეიცავს მონაცემებს (პასკალის ენაზე დაშვებული ნებისმიერი ტიპი), ველი N (NEXT) არის სიის შემდეგი ელემენტის მაჩვენებელი.
თითოეულ სიას უნდა ჰქონდეს შემდეგი მაჩვენებლები: Head - სიის თავი, Cur - სიის მიმდინარე ელემენტი, ზოგჯერ ცალკე დაკავშირებულ სიებში ასევე გამოიყენება Tail pointer - სიის კუდი (ორმაგად დაკავშირებულ სიებში ეს არის ყოველთვის გამოიყენება). სიის ბოლო ელემენტის ინდექსის ველი ცარიელია, ის შეიცავს სპეციალურ ნიშანს Nil, რომელიც მიუთითებს სიის დასასრულს და მითითებულია გადახაზული კვადრატით.
ორმაგად დაკავშირებული წრფივი სია განსხვავდება ცალკე დაკავშირებული სიისგან იმით, რომ სიის თითოეულ კვანძში არის სხვა მაჩვენებელი B (უკან), რომელიც ეხება სიის წინა ელემენტს (ნახ. 11.5).  ).
).
მონაცემთა სტრუქტურა, რომელიც შეესაბამება ორმაგად დაკავშირებულ ხაზოვან სიას, აღწერილია პასკალში შემდეგნაირად:
მარკერი">
ალგორითმების შემუშავების მეთოდები n უხეში ძალის მეთოდი ("უხეში ძალა") n დაშლის მეთოდი n პრობლემის ზომის შემცირების მეთოდი n ტრანსფორმაციის მეთოდი n დინამიური პროგრამირება n ხარბი მეთოდები n ძიების შემცირების მეთოდები n ... © T. A. Pavlovskaya (SPb NRU ITMO) 1

 უხეში ძალის მეთოდი n პრობლემის გადაჭრის პირდაპირი მიდგომა, რომელიც ჩვეულებრივ უშუალოდ ეფუძნება პრობლემის ფორმულირებას და ჩართული ცნებების განმარტებებს. მაგალითი: რიცხვის სიმძლავრის გამოთვლა 1-ის ამ რიცხვზე n-ჯერ n გამოიყენება თითქმის ნებისმიერი ტიპის პრობლემაზე n. ხშირად აღმოჩნდება ყველაზე მარტივი გამოსაყენებელი n იშვიათად აწარმოებს ლამაზ და ეფექტურ ალგორითმებს n უფრო ეფექტური ალგორითმის შემუშავების ღირებულება შეიძლება იყოს აკრძალული, თუ პრობლემის მხოლოდ რამდენიმე მაგალითის გადაჭრაა საჭირო n შეიძლება სასარგებლო იყოს მცირე შემთხვევების გადასაჭრელად პრობლემა. n შეიძლება გახდეს სხვა ალგორითმების ეფექტურობის განსაზღვრის საზომი © ა. პავლოვსკაია (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 3
უხეში ძალის მეთოდი n პრობლემის გადაჭრის პირდაპირი მიდგომა, რომელიც ჩვეულებრივ უშუალოდ ეფუძნება პრობლემის ფორმულირებას და ჩართული ცნებების განმარტებებს. მაგალითი: რიცხვის სიმძლავრის გამოთვლა 1-ის ამ რიცხვზე n-ჯერ n გამოიყენება თითქმის ნებისმიერი ტიპის პრობლემაზე n. ხშირად აღმოჩნდება ყველაზე მარტივი გამოსაყენებელი n იშვიათად აწარმოებს ლამაზ და ეფექტურ ალგორითმებს n უფრო ეფექტური ალგორითმის შემუშავების ღირებულება შეიძლება იყოს აკრძალული, თუ პრობლემის მხოლოდ რამდენიმე მაგალითის გადაჭრაა საჭირო n შეიძლება სასარგებლო იყოს მცირე შემთხვევების გადასაჭრელად პრობლემა. n შეიძლება გახდეს სხვა ალგორითმების ეფექტურობის განსაზღვრის საზომი © ა. პავლოვსკაია (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 3
 n მაგალითი: შერჩევა და ბუშტების დახარისხება 28 -5 © ა. პავლოვსკაია (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 16 0 29 3 -4 56 4.
n მაგალითი: შერჩევა და ბუშტების დახარისხება 28 -5 © ა. პავლოვსკაია (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 16 0 29 3 -4 56 4.
 ამომწურავი ძიება არის უხეში ძალის მიდგომა კომბინატორული პრობლემებისადმი. იგი მოიცავს: n ყველა შესაძლო ელემენტის გენერირებას პრობლემის განსაზღვრის სფეროდან n შერჩევას, რომელიც აკმაყოფილებს პრობლემის პირობით დაწესებულ შეზღუდვებს, n სასურველი ელემენტის ძიებას (მაგალითად, პრობლემის ობიექტური ფუნქციის მნიშვნელობის ოპტიმიზაცია). მაგალითები: მოგზაური გამყიდველის პრობლემა: იპოვნეთ უმოკლესი გზა განიხილეთ n ობიექტის მოცემული ნაკრების ყველა ქვეჯგუფი, მოცემული N ქალაქი, ისე, რომ თითოეულ ქალაქში გამოთვალეთ მხოლოდ თითოეული მათგანის ჯამური წონა დასაშვებობის დასადგენად ერთხელ და საბოლოო დანიშნულება არის ორიგინალი. აირჩიეთ სწორი ქვეჯგუფიდან მაქსიმალური წონით. n მიიღეთ ყველა შესაძლო მარშრუტი Knapsack-ის ყველა ამოცანის გენერირებით: მოცემული წონის N ელემენტი და ზურგჩანთის ღირებულება, რომელსაც შეუძლია გაუძლოს W წონას. ჩატვირთეთ ჩანთა n - 1 შუალედური ქალაქის პერმუტაციებით, გამოთვალეთ მაქსიმალური ღირებულებით. შესაბამისი ბილიკების სიგრძე და უმოკლესის პოვნა. ეს არის NP-მყარი ამოცანები (არ არსებობს ცნობილი ალგორითმი, რომელიც ხსნის მათ პოლინომიურ დროში). n ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 5
ამომწურავი ძიება არის უხეში ძალის მიდგომა კომბინატორული პრობლემებისადმი. იგი მოიცავს: n ყველა შესაძლო ელემენტის გენერირებას პრობლემის განსაზღვრის სფეროდან n შერჩევას, რომელიც აკმაყოფილებს პრობლემის პირობით დაწესებულ შეზღუდვებს, n სასურველი ელემენტის ძიებას (მაგალითად, პრობლემის ობიექტური ფუნქციის მნიშვნელობის ოპტიმიზაცია). მაგალითები: მოგზაური გამყიდველის პრობლემა: იპოვნეთ უმოკლესი გზა განიხილეთ n ობიექტის მოცემული ნაკრების ყველა ქვეჯგუფი, მოცემული N ქალაქი, ისე, რომ თითოეულ ქალაქში გამოთვალეთ მხოლოდ თითოეული მათგანის ჯამური წონა დასაშვებობის დასადგენად ერთხელ და საბოლოო დანიშნულება არის ორიგინალი. აირჩიეთ სწორი ქვეჯგუფიდან მაქსიმალური წონით. n მიიღეთ ყველა შესაძლო მარშრუტი Knapsack-ის ყველა ამოცანის გენერირებით: მოცემული წონის N ელემენტი და ზურგჩანთის ღირებულება, რომელსაც შეუძლია გაუძლოს W წონას. ჩატვირთეთ ჩანთა n - 1 შუალედური ქალაქის პერმუტაციებით, გამოთვალეთ მაქსიმალური ღირებულებით. შესაბამისი ბილიკების სიგრძე და უმოკლესის პოვნა. ეს არის NP-მყარი ამოცანები (არ არსებობს ცნობილი ალგორითმი, რომელიც ხსნის მათ პოლინომიურ დროში). n ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 5

 დაშლის მეთოდი ასევე არის „გაყავი და იბატონე“ მეთოდი: n ამოცანის მაგალითი იყოფა ერთი და იმავე ამოცანის რამდენიმე პატარა ინსტანციად, იდეალურად ერთი და იგივე ზომის. n პრობლემის მცირე ინსტანციები მოგვარებულია (ჩვეულებრივ, რეკურსიულად, თუმცა ხანდახან სხვა ალგორითმი გამოიყენება მცირე შემთხვევებისთვის). n საჭიროების შემთხვევაში, თავდაპირველი პრობლემის გადაწყვეტა გვხვდება მცირე ინსტანციების გადაწყვეტილებების კომბინაციით. დაშლის მეთოდი იდეალურია პარალელური გამოთვლებისთვის. © Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 7
დაშლის მეთოდი ასევე არის „გაყავი და იბატონე“ მეთოდი: n ამოცანის მაგალითი იყოფა ერთი და იმავე ამოცანის რამდენიმე პატარა ინსტანციად, იდეალურად ერთი და იგივე ზომის. n პრობლემის მცირე ინსტანციები მოგვარებულია (ჩვეულებრივ, რეკურსიულად, თუმცა ხანდახან სხვა ალგორითმი გამოიყენება მცირე შემთხვევებისთვის). n საჭიროების შემთხვევაში, თავდაპირველი პრობლემის გადაწყვეტა გვხვდება მცირე ინსტანციების გადაწყვეტილებების კომბინაციით. დაშლის მეთოდი იდეალურია პარალელური გამოთვლებისთვის. © Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 7
 განმეორებითი დაშლის განტოლება n ზოგადად, n ზომის ამოცანის მაგალითი შეიძლება დაიყოს n/b ზომის რამდენიმე ინსტანციად, საიდანაც საჭიროა მისი ამოხსნა. n განზოგადებული განმეორებადი დაშლის განტოლება: (1) n სიმარტივისთვის, ვარაუდობენ, რომ ზომა n უდრის b სიმძლავრის. n ზრდის რიგი დამოკიდებულია a, b და f. © ა. პავლოვსკაია (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 8
განმეორებითი დაშლის განტოლება n ზოგადად, n ზომის ამოცანის მაგალითი შეიძლება დაიყოს n/b ზომის რამდენიმე ინსტანციად, საიდანაც საჭიროა მისი ამოხსნა. n განზოგადებული განმეორებადი დაშლის განტოლება: (1) n სიმარტივისთვის, ვარაუდობენ, რომ ზომა n უდრის b სიმძლავრის. n ზრდის რიგი დამოკიდებულია a, b და f. © ა. პავლოვსკაია (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 8
 დაშლის ძირითადი თეორემა (1) n თქვენ შეგიძლიათ მიუთითოთ ალგორითმის ეფექტურობის კლასი თავად განმეორებითი განტოლების ამოხსნის გარეშე. n ეს მიდგომა საშუალებას გაძლევთ დაადგინოთ ხსნარის ზრდის რიგი უცნობი ფაქტორების განსაზღვრის გარეშე. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 9
დაშლის ძირითადი თეორემა (1) n თქვენ შეგიძლიათ მიუთითოთ ალგორითმის ეფექტურობის კლასი თავად განმეორებითი განტოლების ამოხსნის გარეშე. n ეს მიდგომა საშუალებას გაძლევთ დაადგინოთ ხსნარის ზრდის რიგი უცნობი ფაქტორების განსაზღვრის გარეშე. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 9
 Merge Sort ახარისხებს მოცემულ მასივს ორ ნაწილად გაყოფით, ყოველი ნახევრის რეკურსიულად დახარისხებით და ორი დალაგებული ნახევრის ერთ დახარისხებულ მასივში შერწყმით: შერწყმა (A) თუ n>1 პირველი ნახევარი A -> მასივი B მეორე ნახევარში -> მასივში C Mergesort(B) Mergesort(C) Merge(B, C, A) // შერწყმა © Pavlovskaya T. A. (SPb NRU ITMO) 10
Merge Sort ახარისხებს მოცემულ მასივს ორ ნაწილად გაყოფით, ყოველი ნახევრის რეკურსიულად დახარისხებით და ორი დალაგებული ნახევრის ერთ დახარისხებულ მასივში შერწყმით: შერწყმა (A) თუ n>1 პირველი ნახევარი A -> მასივი B მეორე ნახევარში -> მასივში C Mergesort(B) Mergesort(C) Merge(B, C, A) // შერწყმა © Pavlovskaya T. A. (SPb NRU ITMO) 10
Src="http://present5.com/presentation/54441564_438337950/image-11.jpg" alt="Morgesort (A) if n>1 პირველი ნახევარი A -> B მასივი A-ს მეორე ნახევარში"> Mergesort (A) if n>1 Первая половина А -> в массив В Вторая половина А > в массив С Mergesort(B) Mergesort(C) Меrgе(В, С, А) ©Павловская Т. А. (СПб НИУ ИТМО) 11!}
 მასივების შერწყმა n მასივის ორი ინდექსი ინიციალიზაციის შემდეგ მიუთითებს შერწყმული მასივების პირველ ელემენტებზე. n ელემენტები შედარებულია და პატარა ემატება ახალ მასივს. n პატარა ელემენტის ინდექსი იზრდება (ის მიუთითებს ელემენტზე, რომელიც ახლახანს კოპირებულია). ეს ოპერაცია მეორდება მანამ, სანამ ერთ-ერთი გაერთიანებული მასივი ამოიწურება. მეორე მასივის დარჩენილი ელემენტები ემატება ახალი მასივის ბოლოს. © Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 12
მასივების შერწყმა n მასივის ორი ინდექსი ინიციალიზაციის შემდეგ მიუთითებს შერწყმული მასივების პირველ ელემენტებზე. n ელემენტები შედარებულია და პატარა ემატება ახალ მასივს. n პატარა ელემენტის ინდექსი იზრდება (ის მიუთითებს ელემენტზე, რომელიც ახლახანს კოპირებულია). ეს ოპერაცია მეორდება მანამ, სანამ ერთ-ერთი გაერთიანებული მასივი ამოიწურება. მეორე მასივის დარჩენილი ელემენტები ემატება ახალი მასივის ბოლოს. © Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 12
 შერწყმის დახარისხების ანალიზი n დაე, ფაილის სიგრძე იყოს 2-ის სიმძლავრე. n საკვანძო შედარებების რაოდენობა: C(n) = 2*C(n/2) + Cmerge (n) n > 1, C(1)=0 n Cmerge (n) = n-1 ცუდ შემთხვევაში (საკვანძო შედარებების რაოდენობა შერწყმისას) n უარეს შემთხვევაში Cw: d=1 a=2 b=2 Cw(n) = 2*Cw (n/2) +n -1 Cw (n ) (n log n) – ძირითადის მიხედვით. თეორემა © Pavlovskaya T. A. (SPb NRU ITMO) (1) 13
შერწყმის დახარისხების ანალიზი n დაე, ფაილის სიგრძე იყოს 2-ის სიმძლავრე. n საკვანძო შედარებების რაოდენობა: C(n) = 2*C(n/2) + Cmerge (n) n > 1, C(1)=0 n Cmerge (n) = n-1 ცუდ შემთხვევაში (საკვანძო შედარებების რაოდენობა შერწყმისას) n უარეს შემთხვევაში Cw: d=1 a=2 b=2 Cw(n) = 2*Cw (n/2) +n -1 Cw (n ) (n log n) – ძირითადის მიხედვით. თეორემა © Pavlovskaya T. A. (SPb NRU ITMO) (1) 13
 n შერწყმის დახარისხებით შესრულებული ძირითადი შედარებების რაოდენობა, უარეს შემთხვევაში, ძალიან ახლოსაა შედარებების თეორიულ მინიმალურ რაოდენობასთან შედარების დაფუძნებული დალაგების ალგორითმისთვის. n შერწყმის დახარისხების მთავარი მინუსი არის დამატებითი მეხსიერების საჭიროება, რომლის ოდენობა წრფივი პროპორციულია შეყვანის მონაცემების ზომისა. © ა. პავლოვსკაია (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 14
n შერწყმის დახარისხებით შესრულებული ძირითადი შედარებების რაოდენობა, უარეს შემთხვევაში, ძალიან ახლოსაა შედარებების თეორიულ მინიმალურ რაოდენობასთან შედარების დაფუძნებული დალაგების ალგორითმისთვის. n შერწყმის დახარისხების მთავარი მინუსი არის დამატებითი მეხსიერების საჭიროება, რომლის ოდენობა წრფივი პროპორციულია შეყვანის მონაცემების ზომისა. © ა. პავლოვსკაია (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 14
 სწრაფი დალაგება შერწყმის დალაგებისგან განსხვავებით, რომელიც ჰყოფს მასივის ელემენტებს მათი პოზიციის მიხედვით მასივში, სწრაფი დალაგება გამოყოფს მასივის ელემენტებს მათი მნიშვნელობების მიხედვით. 28 56 ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 1 0 29 3 -4 16 15
სწრაფი დალაგება შერწყმის დალაგებისგან განსხვავებით, რომელიც ჰყოფს მასივის ელემენტებს მათი პოზიციის მიხედვით მასივში, სწრაფი დალაგება გამოყოფს მასივის ელემენტებს მათი მნიშვნელობების მიხედვით. 28 56 ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 1 0 29 3 -4 16 15
 ალგორითმის აღწერა n აირჩიეთ საცნობარო ელემენტი n შეასრულეთ ელემენტების პერმუტაცია დანაყოფის მისაღებად, როდესაც ყველა ელემენტი ზოგიერთ პოზიციამდე s არ აღემატება A [s] ელემენტს, ხოლო ელემენტები s პოზიციის შემდეგ არ არის მასზე ნაკლები. n ცხადია, დაყოფის შემდეგ A [s] არის საბოლოო პოზიციაზე და ჩვენ შეგვიძლია დამოუკიდებლად დავახარისხოთ ელემენტების ორი ქვემაივი A [s]-მდე და შემდეგ (იგივე ან განსხვავებული მეთოდით) © T. A. Pavlovskaya (SPb NRU ITMO) 16
ალგორითმის აღწერა n აირჩიეთ საცნობარო ელემენტი n შეასრულეთ ელემენტების პერმუტაცია დანაყოფის მისაღებად, როდესაც ყველა ელემენტი ზოგიერთ პოზიციამდე s არ აღემატება A [s] ელემენტს, ხოლო ელემენტები s პოზიციის შემდეგ არ არის მასზე ნაკლები. n ცხადია, დაყოფის შემდეგ A [s] არის საბოლოო პოზიციაზე და ჩვენ შეგვიძლია დამოუკიდებლად დავახარისხოთ ელემენტების ორი ქვემაივი A [s]-მდე და შემდეგ (იგივე ან განსხვავებული მეთოდით) © T. A. Pavlovskaya (SPb NRU ITMO) 16
 ელემენტების გადატანის პროცედურა n ეფექტური მეთოდი, დაფუძნებულია ქვემწვავის ორ უღელტეხილზე - მარცხნიდან მარჯვნივ და მარჯვნივ მარცხნივ. თითოეულ უღელტეხილზე ელემენტები შედარებულია მითითებასთან. n გადასასვლელი მარცხნიდან მარჯვნივ (i) გამოტოვებს მითითებაზე პატარა ელემენტებს და ჩერდება მითითებაზე არანაკლებ პირველ ელემენტზე. n მარჯვნიდან მარცხნივ გადასასვლელი (j) გამოტოვებს მითითებაზე დიდ ელემენტებს და ჩერდება პირველ ელემენტზე, რომელიც არ აღემატება მითითებას. n თუ სკანირების ინდექსები არ იკვეთება, ვცვლით ნაპოვნი ელემენტებს და ვაგრძელებთ პასებს. n თუ ინდექსები იკვეთება, შეცვალეთ დამხმარე ელემენტი Aj © T. A. Pavlovskaya (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 17
ელემენტების გადატანის პროცედურა n ეფექტური მეთოდი, დაფუძნებულია ქვემწვავის ორ უღელტეხილზე - მარცხნიდან მარჯვნივ და მარჯვნივ მარცხნივ. თითოეულ უღელტეხილზე ელემენტები შედარებულია მითითებასთან. n გადასასვლელი მარცხნიდან მარჯვნივ (i) გამოტოვებს მითითებაზე პატარა ელემენტებს და ჩერდება მითითებაზე არანაკლებ პირველ ელემენტზე. n მარჯვნიდან მარცხნივ გადასასვლელი (j) გამოტოვებს მითითებაზე დიდ ელემენტებს და ჩერდება პირველ ელემენტზე, რომელიც არ აღემატება მითითებას. n თუ სკანირების ინდექსები არ იკვეთება, ვცვლით ნაპოვნი ელემენტებს და ვაგრძელებთ პასებს. n თუ ინდექსები იკვეთება, შეცვალეთ დამხმარე ელემენტი Aj © T. A. Pavlovskaya (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 17
 სწრაფი დალაგების ეფექტურობა n საუკეთესო შემთხვევაში: ყველა დანაყოფი მთავრდება შესაბამისი ქვემასივების შუაში n უარეს შემთხვევაში, ყველა დანაყოფი ისეთი გამოდის, რომ ერთ-ერთი ქვემაივი ცარიელია, ხოლო მეორის ზომა 1-ით ნაკლებია. დანაწევრებული მასივის ზომა (კვადრატული დამოკიდებულება). n საშუალო შემთხვევაში, ჩვენ ვვარაუდობთ, რომ დანაყოფი შეიძლება შესრულდეს თითოეულ პოზიციაზე ერთი და იგივე ალბათობით: Cavg 2 n ln n 1, 38 n log 2 n © T. A. Pavlovskaya (SPb NRU ITMO) 18
სწრაფი დალაგების ეფექტურობა n საუკეთესო შემთხვევაში: ყველა დანაყოფი მთავრდება შესაბამისი ქვემასივების შუაში n უარეს შემთხვევაში, ყველა დანაყოფი ისეთი გამოდის, რომ ერთ-ერთი ქვემაივი ცარიელია, ხოლო მეორის ზომა 1-ით ნაკლებია. დანაწევრებული მასივის ზომა (კვადრატული დამოკიდებულება). n საშუალო შემთხვევაში, ჩვენ ვვარაუდობთ, რომ დანაყოფი შეიძლება შესრულდეს თითოეულ პოზიციაზე ერთი და იგივე ალბათობით: Cavg 2 n ln n 1, 38 n log 2 n © T. A. Pavlovskaya (SPb NRU ITMO) 18
 ალგორითმის გაუმჯობესება n საცნობარო ელემენტის არჩევის გაუმჯობესებული მეთოდები n მცირე ქვემასივებისთვის უფრო მარტივ დახარისხებაზე გადასვლა n რეკურსიის მოხსნა ყველა ამ გაუმჯობესებამ შეიძლება შეამციროს ალგორითმის მუშაობის დრო 20 -25%-ით (R. Sedgwick) © T. A. Pavlovskaya (SPb NRU ITMO) 19
ალგორითმის გაუმჯობესება n საცნობარო ელემენტის არჩევის გაუმჯობესებული მეთოდები n მცირე ქვემასივებისთვის უფრო მარტივ დახარისხებაზე გადასვლა n რეკურსიის მოხსნა ყველა ამ გაუმჯობესებამ შეიძლება შეამციროს ალგორითმის მუშაობის დრო 20 -25%-ით (R. Sedgwick) © T. A. Pavlovskaya (SPb NRU ITMO) 19
 ორობითი ხის გავლა ეს არის დაშლის მეთოდის გამოყენების კიდევ ერთი მაგალითი n წინასწარი კვეთის დროს, ჯერ ხის ფესვი, შემდეგ კი მარცხენა და მარჯვენა ქვეხეები. n სიმეტრიულ ტრავერსალში ფესვს ნახულობენ მარცხენა ქვეხის შემდეგ, ოღონდ მარჯვენას მონახულებამდე. n საპირისპირო ტრავერსის დროს ფესვი მონახულებულია მარცხენა და მარჯვენა ქვეხეების შემდეგ. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 20
ორობითი ხის გავლა ეს არის დაშლის მეთოდის გამოყენების კიდევ ერთი მაგალითი n წინასწარი კვეთის დროს, ჯერ ხის ფესვი, შემდეგ კი მარცხენა და მარჯვენა ქვეხეები. n სიმეტრიულ ტრავერსალში ფესვს ნახულობენ მარცხენა ქვეხის შემდეგ, ოღონდ მარჯვენას მონახულებამდე. n საპირისპირო ტრავერსის დროს ფესვი მონახულებულია მარცხენა და მარჯვენა ქვეხეების შემდეგ. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 20
 ხის პროცედურის გავლა print_tree(tree); start print_tree(left_subtree) ეწვიეთ root print_tree(right_subtree) ბოლოს; 1 6 8 10 20 ©Pavlovskaya T. A. (სანქტ-პეტერბურგის სახელმწიფო უნივერსიტეტი ITMO) 21 25 30 21
ხის პროცედურის გავლა print_tree(tree); start print_tree(left_subtree) ეწვიეთ root print_tree(right_subtree) ბოლოს; 1 6 8 10 20 ©Pavlovskaya T. A. (სანქტ-პეტერბურგის სახელმწიფო უნივერსიტეტი ITMO) 21 25 30 21

 პრობლემის ზომის შემცირების მეთოდი ემყარება კავშირის გამოყენებას მოცემული პრობლემის ამოხსნისა და იმავე პრობლემის მცირე ინსტანციის ამოხსნას შორის. როდესაც ასეთი ურთიერთობა დამყარდება, ის შეიძლება გამოყენებულ იქნას როგორც ზემოდან ქვევით (რეკურსიულად) ან ქვემოდან ზევით (არარეკურსიული). (მაგალითი - რიცხვის ხარისხამდე გაზრდა) არსებობს ზომის შემცირების მეთოდის სამი ძირითადი ვარიანტი: n შემცირება მუდმივი რაოდენობით (ჩვეულებრივ 1-ით); n შემცირება მუდმივი ფაქტორით (ჩვეულებრივ 2-ჯერ); n ცვლადი ზომის შემცირება. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 23
პრობლემის ზომის შემცირების მეთოდი ემყარება კავშირის გამოყენებას მოცემული პრობლემის ამოხსნისა და იმავე პრობლემის მცირე ინსტანციის ამოხსნას შორის. როდესაც ასეთი ურთიერთობა დამყარდება, ის შეიძლება გამოყენებულ იქნას როგორც ზემოდან ქვევით (რეკურსიულად) ან ქვემოდან ზევით (არარეკურსიული). (მაგალითი - რიცხვის ხარისხამდე გაზრდა) არსებობს ზომის შემცირების მეთოდის სამი ძირითადი ვარიანტი: n შემცირება მუდმივი რაოდენობით (ჩვეულებრივ 1-ით); n შემცირება მუდმივი ფაქტორით (ჩვეულებრივ 2-ჯერ); n ცვლადი ზომის შემცირება. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 23
 Insertion Sort დავუშვათ, რომ n-1 განზომილების მასივის დახარისხების პრობლემა მოგვარებულია. შემდეგ რჩება მხოლოდ An-ის ჩასმა სწორ ადგილას: n მასივის დათვალიერება მარცხნიდან მარჯვნივ n მასივის დათვალიერება მარჯვნიდან მარცხნივ n ორობითი ძიების გამოყენება ჩასმის ადგილისთვის n თუმცა ჩასმის დალაგება ეფუძნება რეკურსიულ მიდგომას , უფრო ეფექტურია მისი განხორციელება ქვემოდან ზევით (იტერატიული). ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 24
Insertion Sort დავუშვათ, რომ n-1 განზომილების მასივის დახარისხების პრობლემა მოგვარებულია. შემდეგ რჩება მხოლოდ An-ის ჩასმა სწორ ადგილას: n მასივის დათვალიერება მარცხნიდან მარჯვნივ n მასივის დათვალიერება მარჯვნიდან მარცხნივ n ორობითი ძიების გამოყენება ჩასმის ადგილისთვის n თუმცა ჩასმის დალაგება ეფუძნება რეკურსიულ მიდგომას , უფრო ეფექტურია მისი განხორციელება ქვემოდან ზევით (იტერატიული). ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 24
 ფსევდოკოდის განხორციელება i = 1-დან n-მდე - 1 do v = 0 და A[j] > v do A
ფსევდოკოდის განხორციელება i = 1-დან n-მდე - 1 do v = 0 და A[j] > v do A
 ჩასმის დახარისხების ეფექტურობა n უარესი შემთხვევა: ასრულებს იმავე რაოდენობის შედარებებს, როგორც შერჩევის დალაგება n საუკეთესო შემთხვევა (თავდაპირველად დალაგებული მასივისთვის): ადარებს მხოლოდ 1 დროს გარე მარყუჟის ყოველი გავლისთვის n საშუალო შემთხვევა (შემთხვევითი მასივი): ასრულებს ~2 ჯერ ნაკლები შედარება, ვიდრე დაღმავალი მასივის შემთხვევაში. რომ. , საშუალო შემთხვევა 2-ჯერ უკეთესია უარეს შემთხვევაში. თითქმის დალაგებული მასივების მაღალ შესრულებასთან ერთად, ეს განასხვავებს ჩასმის დალაგებას სხვა ელემენტარული (შერჩევისა და ბუშტის) ალგორითმებისგან. n ჩასმის დალაგების გაფართოება, Shell sort, უზრუნველყოფს კიდევ უფრო უკეთეს ალგორითმს საკმაოდ დიდი ფაილების დასალაგებლად. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 26
ჩასმის დახარისხების ეფექტურობა n უარესი შემთხვევა: ასრულებს იმავე რაოდენობის შედარებებს, როგორც შერჩევის დალაგება n საუკეთესო შემთხვევა (თავდაპირველად დალაგებული მასივისთვის): ადარებს მხოლოდ 1 დროს გარე მარყუჟის ყოველი გავლისთვის n საშუალო შემთხვევა (შემთხვევითი მასივი): ასრულებს ~2 ჯერ ნაკლები შედარება, ვიდრე დაღმავალი მასივის შემთხვევაში. რომ. , საშუალო შემთხვევა 2-ჯერ უკეთესია უარეს შემთხვევაში. თითქმის დალაგებული მასივების მაღალ შესრულებასთან ერთად, ეს განასხვავებს ჩასმის დალაგებას სხვა ელემენტარული (შერჩევისა და ბუშტის) ალგორითმებისგან. n ჩასმის დალაგების გაფართოება, Shell sort, უზრუნველყოფს კიდევ უფრო უკეთეს ალგორითმს საკმაოდ დიდი ფაილების დასალაგებლად. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 26

 კომბინატორიული ობიექტების გენერირება n კომბინატორიული ობიექტების ყველაზე მნიშვნელოვანი ტიპებია მოცემული სიმრავლის პერმუტაციები, კომბინაციები და ქვესიმრავლეები. n ისინი, როგორც წესი, წარმოიქმნება პრობლემებში, რომლებიც საჭიროებენ სხვადასხვა არჩევანის განხილვას. n გარდა ამისა, არსებობს განლაგებისა და დაყოფის ცნებები. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 28
კომბინატორიული ობიექტების გენერირება n კომბინატორიული ობიექტების ყველაზე მნიშვნელოვანი ტიპებია მოცემული სიმრავლის პერმუტაციები, კომბინაციები და ქვესიმრავლეები. n ისინი, როგორც წესი, წარმოიქმნება პრობლემებში, რომლებიც საჭიროებენ სხვადასხვა არჩევანის განხილვას. n გარდა ამისა, არსებობს განლაგებისა და დაყოფის ცნებები. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 28
 პერმუტაციების გენერაცია პერმუტაციების რაოდენობა n მოცემულია n-ელემენტების სიმრავლე (სიმრავლე). n პერმუტაციაში პირველი ადგილი შეიძლება იყოს ნებისმიერი ელემენტი, ანუ არსებობს პირველი ელემენტის არჩევის n გზა. n დარჩა (n-1) ელემენტები მეორე ელემენტის ასარჩევად პერმუტაციაში (არსებობს (n-1) გზები მეორე ელემენტის ასარჩევად). n დარჩენილია (n-2) ელემენტი მესამე ელემენტის ასარჩევად პერმუტაციაში და ა.შ. n სულ, n-ელემენტების მოწესრიგებული სიმრავლის მიღება შესაძლებელია: გზებით © T. A. Pavlovskaya (SPb NRU ITMO) 29
პერმუტაციების გენერაცია პერმუტაციების რაოდენობა n მოცემულია n-ელემენტების სიმრავლე (სიმრავლე). n პერმუტაციაში პირველი ადგილი შეიძლება იყოს ნებისმიერი ელემენტი, ანუ არსებობს პირველი ელემენტის არჩევის n გზა. n დარჩა (n-1) ელემენტები მეორე ელემენტის ასარჩევად პერმუტაციაში (არსებობს (n-1) გზები მეორე ელემენტის ასარჩევად). n დარჩენილია (n-2) ელემენტი მესამე ელემენტის ასარჩევად პერმუტაციაში და ა.შ. n სულ, n-ელემენტების მოწესრიგებული სიმრავლის მიღება შესაძლებელია: გზებით © T. A. Pavlovskaya (SPb NRU ITMO) 29
 ზომის შემცირების მეთოდის გამოყენება n-ის ყველა პერმუტაციის მიღების პრობლემაზე სიმარტივისთვის, ჩვენ ვვარაუდობთ, რომ შესაცვლი ელემენტების სიმრავლე არის მთელი რიცხვების სიმრავლე 1-დან n-მდე. n ამოცანა, რომელიც ერთით ნაკლებია, არის ყველა (n - 1) გენერირება! პერმუტაციები. n თუ ვივარაუდებთ, რომ ის მოგვარებულია, ჩვენ შეგვიძლია მივიღოთ უფრო დიდი პრობლემის გადაწყვეტა n-ის ჩასმით თითოეულ n შესაძლო პოზიციაში n - 1 ელემენტის თითოეული პერმუტაციის ელემენტებს შორის. n ამ გზით მიღებული ყველა პერმუტაცია განსხვავებული იქნება და მათი საერთო რაოდენობა: n(n- 1)! = n! n შეგიძლიათ ჩასვათ n ადრე გენერირებულ პერმუტაციებში მარცხნიდან მარჯვნივ ან მარჯვნიდან მარცხნივ. ხელსაყრელია მარჯვნიდან მარცხნივ დაწყება და მიმართულების შეცვლა ყოველ ჯერზე, როცა გადახვალთ ნაკრების ახალ პერმუტაციაზე (1, . . . . , n - 1). ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 30
ზომის შემცირების მეთოდის გამოყენება n-ის ყველა პერმუტაციის მიღების პრობლემაზე სიმარტივისთვის, ჩვენ ვვარაუდობთ, რომ შესაცვლი ელემენტების სიმრავლე არის მთელი რიცხვების სიმრავლე 1-დან n-მდე. n ამოცანა, რომელიც ერთით ნაკლებია, არის ყველა (n - 1) გენერირება! პერმუტაციები. n თუ ვივარაუდებთ, რომ ის მოგვარებულია, ჩვენ შეგვიძლია მივიღოთ უფრო დიდი პრობლემის გადაწყვეტა n-ის ჩასმით თითოეულ n შესაძლო პოზიციაში n - 1 ელემენტის თითოეული პერმუტაციის ელემენტებს შორის. n ამ გზით მიღებული ყველა პერმუტაცია განსხვავებული იქნება და მათი საერთო რაოდენობა: n(n- 1)! = n! n შეგიძლიათ ჩასვათ n ადრე გენერირებულ პერმუტაციებში მარცხნიდან მარჯვნივ ან მარჯვნიდან მარცხნივ. ხელსაყრელია მარჯვნიდან მარცხნივ დაწყება და მიმართულების შეცვლა ყოველ ჯერზე, როცა გადახვალთ ნაკრების ახალ პერმუტაციაზე (1, . . . . , n - 1). ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 30
 მაგალითი (პერმუტაციების აღმავალი თაობა) n 12 21 n 123 132 312 321 231 213 © Pavlovskaya T. A. (SPb NRU ITMO) 31
მაგალითი (პერმუტაციების აღმავალი თაობა) n 12 21 n 123 132 312 321 231 213 © Pavlovskaya T. A. (SPb NRU ITMO) 31
 ჯონსონ-ტროტერის ალგორითმი შემოტანილია მობილური ელემენტის კონცეფცია. თითოეული ელემენტი ასოცირდება ისრთან, ელემენტი ითვლება მობილურად, თუ ისარი მიუთითებს პატარა მეზობელ ელემენტზე. n პირველი პერმუტაციის ინიციალიზაცია მნიშვნელობით 1 2. . . n (ყველა ისარი მარცხნივ) n სანამ არის მობილური ნომერი k do n იპოვნეთ მობილურის უდიდესი ნომერი k შეცვალეთ k და მეზობელი რიცხვი, რომელზეც მითითებულია ისრებით k n n შეცვალეთ ისრების მიმართულება k-ზე მეტი ყველა რიცხვისთვის © პავლოვსკაია T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 32
ჯონსონ-ტროტერის ალგორითმი შემოტანილია მობილური ელემენტის კონცეფცია. თითოეული ელემენტი ასოცირდება ისრთან, ელემენტი ითვლება მობილურად, თუ ისარი მიუთითებს პატარა მეზობელ ელემენტზე. n პირველი პერმუტაციის ინიციალიზაცია მნიშვნელობით 1 2. . . n (ყველა ისარი მარცხნივ) n სანამ არის მობილური ნომერი k do n იპოვნეთ მობილურის უდიდესი ნომერი k შეცვალეთ k და მეზობელი რიცხვი, რომელზეც მითითებულია ისრებით k n n შეცვალეთ ისრების მიმართულება k-ზე მეტი ყველა რიცხვისთვის © პავლოვსკაია T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 32
 ლექსიკოგრაფიული თანმიმდევრობა n იყოს პირველი პერმუტაცია (მაგალითად, 1234 წ.). n თითოეული შემდეგის საპოვნელად: 1. დაასკანირეთ მიმდინარე პერმუტაცია მარჯვნიდან მარცხნივ მეზობელი ელემენტების პირველი წყვილის მოსაძებნად, რომ a[i]
ლექსიკოგრაფიული თანმიმდევრობა n იყოს პირველი პერმუტაცია (მაგალითად, 1234 წ.). n თითოეული შემდეგის საპოვნელად: 1. დაასკანირეთ მიმდინარე პერმუტაცია მარჯვნიდან მარცხნივ მეზობელი ელემენტების პირველი წყვილის მოსაძებნად, რომ a[i]
 მაგალითი ალგორითმის გასაგებად 1234 1243 1324 1342 1423 1432 2134 2143 2314 2341 2413 2431 3124 3142 3214 3241 321143232 2 4 321 ©Pavlovskaya T. A. (St. Petersburg National Research University ITMO) 34
მაგალითი ალგორითმის გასაგებად 1234 1243 1324 1342 1423 1432 2134 2143 2314 2341 2413 2431 3124 3142 3214 3241 321143232 2 4 321 ©Pavlovskaya T. A. (St. Petersburg National Research University ITMO) 34
 n ელემენტის ყველა პერმუტაციის რაოდენობა P(n) = n! ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 35
n ელემენტის ყველა პერმუტაციის რაოდენობა P(n) = n! ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 35
 ქვესიმრავლეები n A სიმრავლე არის B სიმრავლის ქვესიმრავლე, თუ A-ს რომელიმე ელემენტი ასევე ეკუთვნის B-ს: A B ან A B n ნებისმიერი სიმრავლე არის მისი საკუთარი ქვესიმრავლე. ცარიელი ნაკრები არის ნებისმიერი სიმრავლის ქვესიმრავლე. n ყველა ქვესიმრავლეების სიმრავლე აღინიშნება 2 A-ით (მას ასევე უწოდებენ სიმძლავრის სიმრავლეს, სიმძლავრის სიმრავლეს, სიმრავლის ხარისხს, ლოგიკურს, ექსპონენციალურ სიმრავლეს). n n ელემენტისგან შემდგარი სასრული სიმრავლის ქვესიმრავლეების რაოდენობა უდრის 2 n-ს (დასამტკიცებლად იხილეთ ვიკიპედია) © Pavlovskaya T. A. (SPb NRU ITMO) 36
ქვესიმრავლეები n A სიმრავლე არის B სიმრავლის ქვესიმრავლე, თუ A-ს რომელიმე ელემენტი ასევე ეკუთვნის B-ს: A B ან A B n ნებისმიერი სიმრავლე არის მისი საკუთარი ქვესიმრავლე. ცარიელი ნაკრები არის ნებისმიერი სიმრავლის ქვესიმრავლე. n ყველა ქვესიმრავლეების სიმრავლე აღინიშნება 2 A-ით (მას ასევე უწოდებენ სიმძლავრის სიმრავლეს, სიმძლავრის სიმრავლეს, სიმრავლის ხარისხს, ლოგიკურს, ექსპონენციალურ სიმრავლეს). n n ელემენტისგან შემდგარი სასრული სიმრავლის ქვესიმრავლეების რაოდენობა უდრის 2 n-ს (დასამტკიცებლად იხილეთ ვიკიპედია) © Pavlovskaya T. A. (SPb NRU ITMO) 36
 ყველა ქვესიმრავლეების გენერაცია n გამოვიყენოთ ამოცანის ზომის 1-ით შემცირების მეთოდი. n ყველა ქვესიმრავლე A = (a 1, . . . . , an) შეიძლება დაიყოს ორ ჯგუფად - ისინი, რომლებიც შეიცავს ელემენტს an და მათ რომელიც არ შეიცავს მას. n პირველი ჯგუფი არის ყველა ქვესიმრავლე (a 1, . . . , an-1); მეორე ჯგუფის ყველა ელემენტის მიღება შესაძლებელია პირველი ჯგუფის ქვეჯგუფებში an ელემენტის დამატებით. (a 1) (a 2) (a 1, a 2) (a 3) (a 1, a 3) (a 2, a 3) (a 1, a 2, a 3) მოსახერხებელია ბიტის ელემენტების მინიჭება კომპლექტი ხაზების ელემენტებზე: 000 001 010 011 100 101 110 111 n სხვა ბრძანებები: მკვრივი; რუხი კოდი: n 000 001 010 111 100 ©T A. Pavlovskaya (St. Petersburg National Research University ITMO) 37
ყველა ქვესიმრავლეების გენერაცია n გამოვიყენოთ ამოცანის ზომის 1-ით შემცირების მეთოდი. n ყველა ქვესიმრავლე A = (a 1, . . . . , an) შეიძლება დაიყოს ორ ჯგუფად - ისინი, რომლებიც შეიცავს ელემენტს an და მათ რომელიც არ შეიცავს მას. n პირველი ჯგუფი არის ყველა ქვესიმრავლე (a 1, . . . , an-1); მეორე ჯგუფის ყველა ელემენტის მიღება შესაძლებელია პირველი ჯგუფის ქვეჯგუფებში an ელემენტის დამატებით. (a 1) (a 2) (a 1, a 2) (a 3) (a 1, a 3) (a 2, a 3) (a 1, a 2, a 3) მოსახერხებელია ბიტის ელემენტების მინიჭება კომპლექტი ხაზების ელემენტებზე: 000 001 010 011 100 101 110 111 n სხვა ბრძანებები: მკვრივი; რუხი კოდი: n 000 001 010 111 100 ©T A. Pavlovskaya (St. Petersburg National Research University ITMO) 37
 რუხი კოდების გენერაცია n ნაცრისფერი კოდი n ბიტისთვის შეიძლება რეკურსიულად აშენდეს n–1 ბიტის კოდიდან: n კოდების საპირისპირო თანმიმდევრობით ჩაწერით n ორიგინალური და ინვერსიული სიების შეერთებით n ყოველი კოდის დასაწყისში 0-ის მიმაგრებით. ორიგინალური სია და 1 კოდის დასაწყისამდე ინვერსიულ სიაში. მაგალითი: n კოდები n = 2 ბიტისთვის: 00, 01, 10 n კოდების ინვერსიული სია: 10, 11, 00 n კომბინირებული სია: 00, 01, 10, 11, 00 n საწყის სიაში დამატებული ნულები: 000, 001 , 010 , 11, 00 n ინვერსიულ სიაში დამატებული ერთეულები: 000, 001, 010, 111, 100 © Pavlovskaya T. A. (SPb NRU ITMO) 38
რუხი კოდების გენერაცია n ნაცრისფერი კოდი n ბიტისთვის შეიძლება რეკურსიულად აშენდეს n–1 ბიტის კოდიდან: n კოდების საპირისპირო თანმიმდევრობით ჩაწერით n ორიგინალური და ინვერსიული სიების შეერთებით n ყოველი კოდის დასაწყისში 0-ის მიმაგრებით. ორიგინალური სია და 1 კოდის დასაწყისამდე ინვერსიულ სიაში. მაგალითი: n კოდები n = 2 ბიტისთვის: 00, 01, 10 n კოდების ინვერსიული სია: 10, 11, 00 n კომბინირებული სია: 00, 01, 10, 11, 00 n საწყის სიაში დამატებული ნულები: 000, 001 , 010 , 11, 00 n ინვერსიულ სიაში დამატებული ერთეულები: 000, 001, 010, 111, 100 © Pavlovskaya T. A. (SPb NRU ITMO) 38
 K-ელემენტების ქვესიმრავლეები n k-ელემენტების ქვესიმრავლეების რაოდენობას n (0 k n) ეწოდება კომბინაციების რაოდენობა (ბინომიური კოეფიციენტი): n პირდაპირი ამოხსნა არაეფექტურია ფაქტორიალის სწრაფი ზრდის გამო. n როგორც წესი, k-ელემენტების ქვესიმრავლეების გენერირება ხორციელდება ლექსიკოგრაფიული თანმიმდევრობით (ნებისმიერი ორი ქვესიმრავლისთვის, პირველი გენერირებულია ის, რომლის ელემენტის ინდექსების გამოყენება შესაძლებელია n-ში უფრო მცირე k-ნიშნა რიცხვის ფორმირებისთვის. არი რიცხვების სისტემა). n მეთოდი: n კარდინალურობის k ქვესიმრავლის პირველი ელემენტი შეიძლება იყოს ნებისმიერი ელემენტი, დაწყებული პირველიდან და დამთავრებული (n-k+1)-ით. n ქვეჯგუფის პირველი ელემენტის ინდექსის დაფიქსირების შემდეგ, რჩება k-1 ელემენტების შერჩევა პირველზე მეტი ინდექსის მქონე ელემენტებიდან. n გარდა ამისა, ანალოგიურად, პრობლემის შემცირება უფრო მცირე განზომილებამდე ყველაზე დაბალი დონერეკურსია არ შეარჩევს ბოლო ელემენტს, რის შემდეგაც არჩეული ქვეჯგუფი შეიძლება დაიბეჭდოს ან დამუშავდეს. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 39
K-ელემენტების ქვესიმრავლეები n k-ელემენტების ქვესიმრავლეების რაოდენობას n (0 k n) ეწოდება კომბინაციების რაოდენობა (ბინომიური კოეფიციენტი): n პირდაპირი ამოხსნა არაეფექტურია ფაქტორიალის სწრაფი ზრდის გამო. n როგორც წესი, k-ელემენტების ქვესიმრავლეების გენერირება ხორციელდება ლექსიკოგრაფიული თანმიმდევრობით (ნებისმიერი ორი ქვესიმრავლისთვის, პირველი გენერირებულია ის, რომლის ელემენტის ინდექსების გამოყენება შესაძლებელია n-ში უფრო მცირე k-ნიშნა რიცხვის ფორმირებისთვის. არი რიცხვების სისტემა). n მეთოდი: n კარდინალურობის k ქვესიმრავლის პირველი ელემენტი შეიძლება იყოს ნებისმიერი ელემენტი, დაწყებული პირველიდან და დამთავრებული (n-k+1)-ით. n ქვეჯგუფის პირველი ელემენტის ინდექსის დაფიქსირების შემდეგ, რჩება k-1 ელემენტების შერჩევა პირველზე მეტი ინდექსის მქონე ელემენტებიდან. n გარდა ამისა, ანალოგიურად, პრობლემის შემცირება უფრო მცირე განზომილებამდე ყველაზე დაბალი დონერეკურსია არ შეარჩევს ბოლო ელემენტს, რის შემდეგაც არჩეული ქვეჯგუფი შეიძლება დაიბეჭდოს ან დამუშავდეს. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 39
 მაგალითი: 6-დან 3-მდე კომბინაციები #include const int N = 6, K = 3; int a[K]; void rec(int i) ( if (i == K) ( for (int j = 0; j 0 ? a + 1: 1); a[i]
მაგალითი: 6-დან 3-მდე კომბინაციები #include const int N = 6, K = 3; int a[K]; void rec(int i) ( if (i == K) ( for (int j = 0; j 0 ? a + 1: 1); a[i]
 კომბინაციების თვისებები n მოცემული ელემენტების სიმრავლის თითოეული n-ელემენტის ქვესიმრავლე შეესაბამება ერთი და იმავე სიმრავლის მხოლოდ ერთ n-k-ელემენტის ქვესიმრავლეს: n © Pavlovskaya T. A. (SPb NRU ITMO) 41
კომბინაციების თვისებები n მოცემული ელემენტების სიმრავლის თითოეული n-ელემენტის ქვესიმრავლე შეესაბამება ერთი და იმავე სიმრავლის მხოლოდ ერთ n-k-ელემენტის ქვესიმრავლეს: n © Pavlovskaya T. A. (SPb NRU ITMO) 41

 განლაგება n n ელემენტის განლაგება m-ით არის თანმიმდევრობა, რომელიც შედგება ზოგიერთი n ელემენტის ნაკრების m სხვადასხვა ელემენტისგან (კომბინაციები, რომლებიც შედგება მოცემული n ელემენტისგან m ელემენტის მიხედვით და განსხვავდებიან როგორც თავად ელემენტებით, ასევე ელემენტების თანმიმდევრობით. განსხვავებები კომბინაციებისა და განლაგების განმარტებებში: n კომბინაცია – n-დან m ელემენტებს შეიცავს (ელემენტების რიგი არ არის მნიშვნელოვანი). n განლაგება არის მიმდევრობა, რომელიც შეიცავს m ელემენტებს n-დან (მნიშვნელოვანია ელემენტების რიგი). მიმდევრობის ფორმირებისას მნიშვნელოვანია ელემენტების თანმიმდევრობა, მაგრამ ქვესიმრავლის ფორმირებისას თანმიმდევრობა არ არის მნიშვნელოვანი. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის სახელმწიფო უნივერსიტეტი ITMO) 44
განლაგება n n ელემენტის განლაგება m-ით არის თანმიმდევრობა, რომელიც შედგება ზოგიერთი n ელემენტის ნაკრების m სხვადასხვა ელემენტისგან (კომბინაციები, რომლებიც შედგება მოცემული n ელემენტისგან m ელემენტის მიხედვით და განსხვავდებიან როგორც თავად ელემენტებით, ასევე ელემენტების თანმიმდევრობით. განსხვავებები კომბინაციებისა და განლაგების განმარტებებში: n კომბინაცია – n-დან m ელემენტებს შეიცავს (ელემენტების რიგი არ არის მნიშვნელოვანი). n განლაგება არის მიმდევრობა, რომელიც შეიცავს m ელემენტებს n-დან (მნიშვნელოვანია ელემენტების რიგი). მიმდევრობის ფორმირებისას მნიშვნელოვანია ელემენტების თანმიმდევრობა, მაგრამ ქვესიმრავლის ფორმირებისას თანმიმდევრობა არ არის მნიშვნელოვანი. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის სახელმწიფო უნივერსიტეტი ITMO) 44
 განლაგების რაოდენობა n განლაგების რაოდენობა n-დან m-მდე: მაგალითი 1: რამდენი ორნიშნა რიცხვია, რომლებშიც ათეულების და ერთეულის ციფრი განსხვავებული და კენტია? ძირითადი ნაკრები: (1, 3, 5, 7, 9) – კენტი რიცხვები, n=5 n კავშირი – ორნიშნა რიცხვი m=2, თანმიმდევრობა მნიშვნელოვანია, რაც ნიშნავს, რომ ეს არის განლაგება „ხუთი ორზე“. n პერმუტაციები შეიძლება ჩაითვალოს განლაგების განსაკუთრებულ შემთხვევად m=n-ით მაგალითი 2: რამდენი გზით შეგიძლიათ გააკეთოთ დროშა, რომელიც შედგება სხვადასხვა ფერის სამი ჰორიზონტალური ზოლისგან, თუ არის ხუთი ფერის მასალა? ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 45
განლაგების რაოდენობა n განლაგების რაოდენობა n-დან m-მდე: მაგალითი 1: რამდენი ორნიშნა რიცხვია, რომლებშიც ათეულების და ერთეულის ციფრი განსხვავებული და კენტია? ძირითადი ნაკრები: (1, 3, 5, 7, 9) – კენტი რიცხვები, n=5 n კავშირი – ორნიშნა რიცხვი m=2, თანმიმდევრობა მნიშვნელოვანია, რაც ნიშნავს, რომ ეს არის განლაგება „ხუთი ორზე“. n პერმუტაციები შეიძლება ჩაითვალოს განლაგების განსაკუთრებულ შემთხვევად m=n-ით მაგალითი 2: რამდენი გზით შეგიძლიათ გააკეთოთ დროშა, რომელიც შედგება სხვადასხვა ფერის სამი ჰორიზონტალური ზოლისგან, თუ არის ხუთი ფერის მასალა? ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 45
 განლაგება გამეორებებით n განლაგება გამეორებით n ელემენტიდან E = (a 1, a 2, . . . . , an) k-ით - ნებისმიერი სასრული მიმდევრობა, რომელიც შედგება მოცემული E სიმრავლის k ელემენტებისაგან. n ორი განლაგება გამეორებით არის განსხვავებულად განიხილება, თუ ერთ ადგილზე მაინც აქვთ E სიმრავლის სხვადასხვა ელემენტები. n სხვადასხვა განლაგების რაოდენობა n-დან k-მდე გამეორებით უდრის nk-ს. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 46
განლაგება გამეორებებით n განლაგება გამეორებით n ელემენტიდან E = (a 1, a 2, . . . . , an) k-ით - ნებისმიერი სასრული მიმდევრობა, რომელიც შედგება მოცემული E სიმრავლის k ელემენტებისაგან. n ორი განლაგება გამეორებით არის განსხვავებულად განიხილება, თუ ერთ ადგილზე მაინც აქვთ E სიმრავლის სხვადასხვა ელემენტები. n სხვადასხვა განლაგების რაოდენობა n-დან k-მდე გამეორებით უდრის nk-ს. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 46
 სიმრავლეების დაყოფა n სიმრავლის დაყოფა არის მისი წარმოდგენა, როგორც თვითნებური რაოდენობის წყვილი განცალკევებული ქვესიმრავლეების გაერთიანება. n n-ელემენტის უწესრიგო ტიხრების რაოდენობა დაყენებულია k ნაწილებად - სტერლინგის რიცხვი მე-2 ტიპის: n n-ელემენტის დალაგებული დანაყოფების რაოდენობა ფიქსირებული ზომის m ნაწილებად დაყენებული - მრავალწევრი კოეფიციენტი: n n-ელემენტების კომპლექტის ყველა დაუწესრიგებელი დანაყოფის რაოდენობა მოცემულია ზარის ნომრით: © Pavlovskaya T. A. (SPb NRU ITMO) 47
სიმრავლეების დაყოფა n სიმრავლის დაყოფა არის მისი წარმოდგენა, როგორც თვითნებური რაოდენობის წყვილი განცალკევებული ქვესიმრავლეების გაერთიანება. n n-ელემენტის უწესრიგო ტიხრების რაოდენობა დაყენებულია k ნაწილებად - სტერლინგის რიცხვი მე-2 ტიპის: n n-ელემენტის დალაგებული დანაყოფების რაოდენობა ფიქსირებული ზომის m ნაწილებად დაყენებული - მრავალწევრი კოეფიციენტი: n n-ელემენტების კომპლექტის ყველა დაუწესრიგებელი დანაყოფის რაოდენობა მოცემულია ზარის ნომრით: © Pavlovskaya T. A. (SPb NRU ITMO) 47
 შემცირების მეთოდი მუდმივი ფაქტორით n მაგალითი: ორობითი ძიება n ასეთი ალგორითმები ლოგარითმულია და, ძალიან სწრაფი, საკმაოდ იშვიათია. ცვლადი ფაქტორით შემცირების მეთოდი n მაგალითები: ძიება და ჩასმა ბინარულ საძიებო ხეში, ინტერპოლაციის ძიება: © Pavlovskaya T. A. (St. Petersburg State University ITMO) 48
შემცირების მეთოდი მუდმივი ფაქტორით n მაგალითი: ორობითი ძიება n ასეთი ალგორითმები ლოგარითმულია და, ძალიან სწრაფი, საკმაოდ იშვიათია. ცვლადი ფაქტორით შემცირების მეთოდი n მაგალითები: ძიება და ჩასმა ბინარულ საძიებო ხეში, ინტერპოლაციის ძიება: © Pavlovskaya T. A. (St. Petersburg State University ITMO) 48
 შესრულების ანალიზი n ინტერპოლაციის ძიება მოითხოვს საშუალოდ ნაკლებ log 2 n+1 გასაღების შედარებებს n შემთხვევითი მნიშვნელობების სიის ძიებისას. n ეს ფუნქცია ისე ნელა იზრდება, რომ ყველა რეალურია პრაქტიკული მნიშვნელობები n ის შეიძლება ჩაითვალოს მუდმივად. n თუმცა, უარეს შემთხვევაში, ინტერპოლაციის ძიება გადაგვარდება წრფივ ძიებაში, რაც განიხილება, როგორც ყველაზე უარესი შესაძლო ძიება. n ინტერპოლაციის ძიება საუკეთესოდ გამოიყენება დიდი ფაილებისთვის და აპლიკაციებისთვის, რომლებშიც მონაცემების შედარება ან წვდომა ძვირადღირებული ოპერაციაა. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 49
შესრულების ანალიზი n ინტერპოლაციის ძიება მოითხოვს საშუალოდ ნაკლებ log 2 n+1 გასაღების შედარებებს n შემთხვევითი მნიშვნელობების სიის ძიებისას. n ეს ფუნქცია ისე ნელა იზრდება, რომ ყველა რეალურია პრაქტიკული მნიშვნელობები n ის შეიძლება ჩაითვალოს მუდმივად. n თუმცა, უარეს შემთხვევაში, ინტერპოლაციის ძიება გადაგვარდება წრფივ ძიებაში, რაც განიხილება, როგორც ყველაზე უარესი შესაძლო ძიება. n ინტერპოლაციის ძიება საუკეთესოდ გამოიყენება დიდი ფაილებისთვის და აპლიკაციებისთვის, რომლებშიც მონაცემების შედარება ან წვდომა ძვირადღირებული ოპერაციაა. ©Pavlovskaya T. A. (სანქტ-პეტერბურგის ეროვნული კვლევითი უნივერსიტეტი ITMO) 49
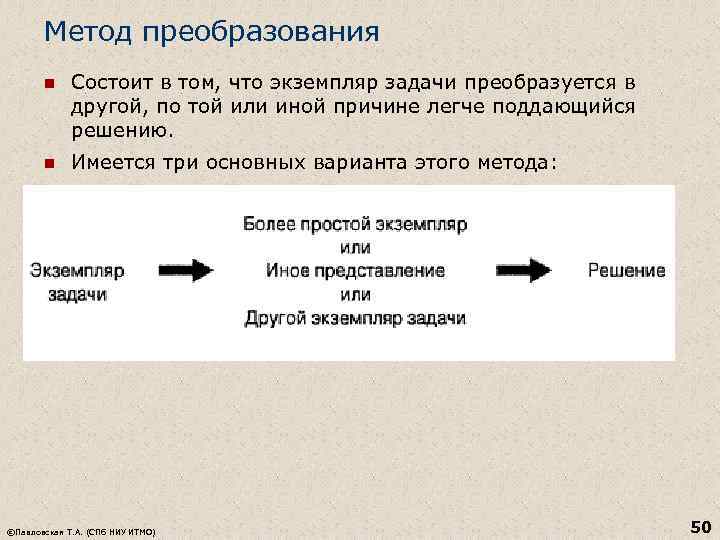 ტრანსფორმაციის მეთოდი n მდგომარეობს იმაში, რომ პრობლემის მაგალითი გარდაიქმნება მეორეში, ამა თუ იმ მიზეზით უფრო ადვილად გადასაჭრელად. n არსებობს ამ მეთოდის სამი ძირითადი ვერსია: ©T A. Pavlovskaya (St. Petersburg National Research University ITMO) 50
ტრანსფორმაციის მეთოდი n მდგომარეობს იმაში, რომ პრობლემის მაგალითი გარდაიქმნება მეორეში, ამა თუ იმ მიზეზით უფრო ადვილად გადასაჭრელად. n არსებობს ამ მეთოდის სამი ძირითადი ვერსია: ©T A. Pavlovskaya (St. Petersburg National Research University ITMO) 50
 მაგალითი 1: მასივის ელემენტების უნიკალურობის შემოწმება n უხეში ძალის ალგორითმი ადარებს ყველა ელემენტს წყვილად, სანამ ორი იდენტური არ მოიძებნება ან სანამ ყველა შესაძლო წყვილი არ განიხილება. უარეს შემთხვევაში, ეფექტურობა არის კვადრატული. n პრობლემას სხვაგვარადაც შეგიძლიათ მიუდგეთ - ჯერ დაალაგეთ მასივი და შემდეგ შეადარეთ მხოლოდ თანმიმდევრული ელემენტები. n ალგორითმის მუშაობის დრო არის დახარისხების დროის ჯამი და მეზობელი ელემენტების შემოწმების დრო. n თუ იყენებთ კარგი დახარისხების ალგორითმს, მასივის ელემენტების უნიკალურობის შემოწმების მთელ ალგორითმს ასევე ექნება O (n log n) ეფექტურობა © T. A. Pavlovskaya (SPb NRU ITMO) 51
მაგალითი 1: მასივის ელემენტების უნიკალურობის შემოწმება n უხეში ძალის ალგორითმი ადარებს ყველა ელემენტს წყვილად, სანამ ორი იდენტური არ მოიძებნება ან სანამ ყველა შესაძლო წყვილი არ განიხილება. უარეს შემთხვევაში, ეფექტურობა არის კვადრატული. n პრობლემას სხვაგვარადაც შეგიძლიათ მიუდგეთ - ჯერ დაალაგეთ მასივი და შემდეგ შეადარეთ მხოლოდ თანმიმდევრული ელემენტები. n ალგორითმის მუშაობის დრო არის დახარისხების დროის ჯამი და მეზობელი ელემენტების შემოწმების დრო. n თუ იყენებთ კარგი დახარისხების ალგორითმს, მასივის ელემენტების უნიკალურობის შემოწმების მთელ ალგორითმს ასევე ექნება O (n log n) ეფექტურობა © T. A. Pavlovskaya (SPb NRU ITMO) 51
უხეში ძალის მეთოდი
სრული ძებნა(ან უხეში ძალის მეთოდიინგლისურიდან უხეში ძალა) - პრობლემის გადაჭრის მეთოდი ყველაში ძიებით შესაძლო ვარიანტები. სრული ძიების სირთულე დამოკიდებულია პრობლემის ყველა შესაძლო გადაწყვეტის სივრცის განზომილებაზე. თუ გადაწყვეტის სივრცე ძალიან დიდია, მაშინ ამომწურავი ძებნა შეიძლება არ გამოიღოს შედეგს რამდენიმე წლის ან თუნდაც საუკუნის განმავლობაში.
ნახეთ, რა არის „უხეში ძალის მეთოდი“ სხვა ლექსიკონებში:
სრული ძებნა (ან "უხეში ძალის" მეთოდი ინგლისური brute force-დან) არის პრობლემის გადაჭრის მეთოდი ყველა შესაძლო ვარიანტის ძიებით. სრული ძიების სირთულე დამოკიდებულია პრობლემის ყველა შესაძლო გადაწყვეტის სივრცის განზომილებაზე. თუ ამოხსნის სივრცე... ... ვიკიპედია
დალაგება მარტივი გაცვლის მიხედვით, ბუშტების დალაგება მარტივი დახარისხების ალგორითმია. ეს ალგორითმი ყველაზე მარტივი გასაგებად და დასანერგად, მაგრამ ეფექტურია მხოლოდ მცირე მასივებისთვის. ალგორითმის სირთულე: O(n²). ალგორითმი... ... ვიკიპედია
ამ ტერმინს სხვა მნიშვნელობა აქვს, იხილეთ Overkill. უხეში ძალა (ან უხეში ძალა) არის მეთოდი მათემატიკური ამოცანების გადაჭრისთვის. მიეკუთვნება ყველა შესაძლო ამოწურვით გამოსავლის პოვნის მეთოდების კლასს... ... ვიკიპედიას
ბროშურის „ბეილის ფურცლები...“ პირველი გამოცემის გარეკანზე, ბეილის კრიპტოგრამები წარმოადგენს სამ დაშიფრულ შეტყობინებას, როგორც მოსალოდნელი იყო, რომელიც შეიცავს ინფორმაციას ოქროს, ვერცხლის და საგანძურის ადგილმდებარეობის შესახებ. ძვირფასი ქვები, სავარაუდოდ დაკრძალულია ტერიტორიაზე ... ვიკიპედია
Snefru არის კრიპტოგრაფიული ცალმხრივი ჰეშის ფუნქცია, რომელიც შემოთავაზებულია რალფ მერკლის მიერ. (თვითონ სახელწოდება სნეფრუ, რომელიც აგრძელებს ბლოკის შიფრების ტრადიციებს ხუფუსა და ხაფრეს, ასევე შემუშავებული რალფ მერკლის მიერ, არის ეგვიპტური ... ... ვიკიპედიის სახელი.
ბლოკის შიფრით დაშიფრული მონაცემების გატეხვის (გაშიფვრის) მცდელობა. ყველა ძირითადი ტიპის თავდასხმა გამოიყენება შიფრების დაბლოკვისთვის, მაგრამ არის შეტევები, რომლებიც სპეციფიკურია მხოლოდ შიფრების დაბლოკვისთვის. სარჩევი 1 თავდასხმების სახეები 1.1 ზოგადი ... ვიკიპედია
ნეიროკრიპტოგრაფია არის კრიპტოგრაფიის ფილიალი, რომელიც სწავლობს სტოქასტური ალგორითმების, კერძოდ ნერვული ქსელების გამოყენებას დაშიფვრისა და კრიპტოანალიზისთვის. სარჩევი 1 განმარტება 2 აპლიკაცია ... ვიკიპედია
ოპტიმალური მარშრუტი მოგზაური გამყიდველისთვის გერმანიის 15 უდიდესი ქალაქის გავლით. მითითებული მარშრუტი არის უმოკლესი ყველა შესაძლო 43,589,145,600 მოგზაურობის გამყიდველის პრობლემა (TSP) (მოგზაური გამყიდველი ... ვიკიპედია
კრიპტოგრაფიული ჰეშის ფუნქცია დასახელება N ჰეში შექმნილია 1990 გამოქვეყნებულია 1990 ჰეშის ზომა 128 ბიტი რაუნდების რაოდენობა 12 ან 15 ჰეშის ფუნქციის ტიპი N ჰეშის კრიპტოგრაფიული ... ვიკიპედია
მოგზაური გამყიდველის პრობლემა (მოგზაური გამყიდველი) ერთ-ერთი ყველაზე გავრცელებულია ცნობილი პრობლემებიკომბინაციური ოპტიმიზაცია. ამოცანაა იპოვოთ ყველაზე მომგებიანი მარშრუტი მითითებულ ქალაქებში ერთხელ მაინც... ... ვიკიპედია